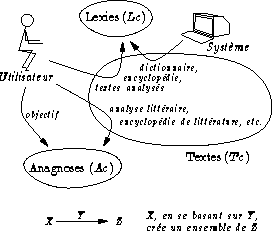
L'ensemble
![]() ,
le corpus, contient la totalité des textes
disponibles. Non seulement les textes que nous voulons analyser mais
aussi les textes qui sont susceptibles de nous donner des informations
sémantiques pour l'analyse des autres textes. Une particularité de
,
le corpus, contient la totalité des textes
disponibles. Non seulement les textes que nous voulons analyser mais
aussi les textes qui sont susceptibles de nous donner des informations
sémantiques pour l'analyse des autres textes. Une particularité de
![]() : en tant qu'ensemble simple, il n'est pas organisé et il n'est
pas constitué de textes de même origine, période, genre etc. Il s'agit
de la << matière textuelle brute >>, le matériau qui sera utilisé plus
tard pour former les entités << interprétables >>. Un texte de
: en tant qu'ensemble simple, il n'est pas organisé et il n'est
pas constitué de textes de même origine, période, genre etc. Il s'agit
de la << matière textuelle brute >>, le matériau qui sera utilisé plus
tard pour former les entités << interprétables >>. Un texte de
![]() ,
pour nous, n'est pas directement interprétable : il manque, pour ce
faire, le contexte de l'interprétation (cf. plus loin).
,
pour nous, n'est pas directement interprétable : il manque, pour ce
faire, le contexte de l'interprétation (cf. plus loin).
Si les éléments de
![]() sont les textes disponibles,
quels sont les éléments de
sont les textes disponibles,
quels sont les éléments de
 et de
et de
 ? La formation de ces
ensembles est fondée sur les textes et dépend de l'utilisateur. Nous
pouvons avoir une première intuition de l'ensemble de lexies en
considérant quelques textes spéciaux (dictionnaires, encyclopédies)
qui sont constitués d'une liste d'entrées. Chaque entrée, est
a priori une lexie4.3, avec une
stabilisation sémantique importante (i.e. utile) pour la structuration
du sens et l'analyse sémantique en général. D'autre part,
l'utilisateur peut définir de nouvelles lexies, qui ne correspondent
pas aux lexies stabilisées des dictionnaires mais qui peuvent
appartenir, par exemple, à l'idiolecte de l'auteur du texte
analysé. Cette sélection des parties d'un texte pour en constituer des
éléments d'une analyse sémantique fait partie du processus de
l'interprétation : << Seuls des signifiants sont transmis : tout le
reste est à reconstruire. En d'autres termes, l'interprétation ne
s'appuie pas sur des signes déjà donnés, elle reconstitue les signes
en identifiant leurs signifiants et en les associant à des
signifiés. L'identification des signes comme tels résulte donc
de parcours interprétatifs. >> [60, p.12].
? La formation de ces
ensembles est fondée sur les textes et dépend de l'utilisateur. Nous
pouvons avoir une première intuition de l'ensemble de lexies en
considérant quelques textes spéciaux (dictionnaires, encyclopédies)
qui sont constitués d'une liste d'entrées. Chaque entrée, est
a priori une lexie4.3, avec une
stabilisation sémantique importante (i.e. utile) pour la structuration
du sens et l'analyse sémantique en général. D'autre part,
l'utilisateur peut définir de nouvelles lexies, qui ne correspondent
pas aux lexies stabilisées des dictionnaires mais qui peuvent
appartenir, par exemple, à l'idiolecte de l'auteur du texte
analysé. Cette sélection des parties d'un texte pour en constituer des
éléments d'une analyse sémantique fait partie du processus de
l'interprétation : << Seuls des signifiants sont transmis : tout le
reste est à reconstruire. En d'autres termes, l'interprétation ne
s'appuie pas sur des signes déjà donnés, elle reconstitue les signes
en identifiant leurs signifiants et en les associant à des
signifiés. L'identification des signes comme tels résulte donc
de parcours interprétatifs. >> [60, p.12].
Quel que soit le moyen de sa constitution, toute lexie est censée être identifiée à un texte du corpus au moins.
Il existe des textes spéciaux (analyses littéraires, histoire de la
littérature, encyclopédies spécialisées) qui parlent de quelques
sous-ensembles de textes << intéressants >> (appelés par exemple genres, ou simplement contexte d'analyse dans le cadre d'une
analyse littéraire plus personnelle). Ces ensembles de textes
constituent des << sociétés textuelles >> qui, comme les lexies
stabilisées dans un dictionnaire, sont généralement considérées comme
utiles (historiquement, d'un point de vu sociologique, etc.). Un
premier ensemble des anagnoses
![]() est basé sur de tels
ensembles. De plus, l'utilisateur définit ses propres ensembles de
textes (plutôt ensembles structurés de textes) et donc ses propres
anagnoses qui correspondent à ses besoins d'analyse.
est basé sur de tels
ensembles. De plus, l'utilisateur définit ses propres ensembles de
textes (plutôt ensembles structurés de textes) et donc ses propres
anagnoses qui correspondent à ses besoins d'analyse.